
未来数字化时代,生产资料就是数据,生产力就是算力,生产关系就是工业互联网,生产工具是大数据和 AI。
1. 大数据基础认知
大数据的定义:数量大、获取速度快或形态多样的数据。难以用传统关系行数据分析方法进行有效分析。
大数据的 4V 特征(*):
- 容量(Volume):非结构化的数据规模更大,增长速度更快。
- 多样性(Variety):数据类型多(文本、图像视频、机器数据),数据无模式或不明显。
- 价值(Value):数据价值密度低,大量不相关信息。
- 高效(Velocity):数据需要实时分析,实时呈现分析结果。
3. 大数据核心技术 (**)
起源于 Google 发布的三篇论文:Google File System、MapReduce、BigTable。
而后 Hadoop 根据这三篇论文设计了三大核心技术:
Google File System -> HDFS(分布式文件系统)
MapReduce -> MapReduce(分布式计算框架)
BigTable -> HBase(分布式列存储数据库)
新型分布式文件系统技术(以 HDFS 为代表)

HDFS(Hadoop distribute file system):分布式文件系统。文件被等分成大小相同的数据块(1 块缺省 128MB),分布在不同的 DataNode 节点上,这时为了找到具体块的位置,需要读取 NameNode (又可以叫:FS 文件系统/NameSpace/meta ops 元操作)中的文件元数据(记录了文件名、文件块、文件块所在的 DataNode)
- 心跳机制:DataNode 会时不时向 NameNode 发送心跳,说:还活着。这样数据存储的时候,就还会把它作为数据存储的节点。
- 负载均衡:当某个 DataNode 的存储达到饱和,DatNode 与 DataNode 之间磁盘利用率不平衡的情况时,HDFS 根据算法对各 DataNode 上数据的存储分布进行调整。
- 副本机制:为了防止数据丢失,HDFS 会将每个块复制成多个副本,分布在不同的 DataNode 节点上。
?DataServing 是什么(后面扩展)
这样的机制让 HDFS 具有三个特点:
- 高可靠:每块文件数据在不同 DataNode 上保存 3 份。
- 高扩展:DataNode 可不断扩展。
- 高吞吐能力:因为保存了 3 份,另一个好处是可方便不同应用就近读取,提高访问效率。
同时HDFS 适合:
- 大规模数据
- 流式数据访问(一次写入,多次读取)
- 商用硬件(一般硬件)
HDFS 不适合:
- 大量的小文件,由于分布存储需要从不同节点读取数据,对于小文件来说效率反而没有集中存储高(一次性读)。
- 频繁修改文件,HDFS不支持文件修改,只支持追加。
HDFS 基于文件系统层面提供文件访问能力,也是海量数据库技术的底层依托。
新型分布式计算框架技术(以 MapReduce 为代表)

MapReduce:是一种用于处理大规模数据集的编程模型和计算框架,分为 Map 阶段,shuffle 阶段和 Reduce 阶段:
- Map 阶段:输入数据被切分成大小相等的数据块,每个数据块被并行地分发和由多个 Map 任务进行映射和处理,生成一系列键-值对。
- Shuffle 阶段:将相同键的值聚合在一起。按键对其进行排序和分组。
- Reduce 阶段:每个 Reduce 任务获取到一个或多个键的值的集合,对这些值进行聚合、计算或其他操作,并生成最终的输出结果。
MapReduce 有着高可靠容错的特点,因为 MapReduce 支持数据备份和恢复,可以在计算节点出现故障时自动重试或重新分配任务。
新型分布式数据库技术(以 HBase 为代表)

HBase:一个分布式、面向列的 NoSQL 数据库,建立在 Hadoop 文件系统(HDFS)之上,HBase 负责存储和管理数据,提供高可靠、高性能的数据访问接口。
RegionServer:HBase 表被水平分割成多个 Region,每个 Region 负责存储一定范围的行键(Row Key)数据,RegionServer 是 HBase 集群中的数据节点,每个 RegionServer 管理若干个 Region,负责存储和处理数据(处理客户端的读写请求,执行数据的增删改查操作)。
HMaster:HMaster 是 HBase 集群的主节点,负责管理和协调整个集群的元数据和状态,处理表的创建、删除、分割、合并等操作,以及 RegionServer 的动态管理和负载均衡。HMaster 还负责监控集群中各个组件的状态,并根据需要进行故障处理和恢复。
元数据(MetaData):描述数据的数据,也可以理解为数据的附加信息,元数据提供了有关数据的各种属性、特征和关系。
ZooKeeper:是一个分布式协调服务,用于管理和维护分布式系统中的配置信息、状态信息和命名服务。HBase 使用 ZooKeeper 来协调和同步各个组件之间的状态和配置信息,如 RegionServer 的状态、表的元数据、负载均衡等。
Ephemeral Node:是 ZooKeeper 中的一种节点类型,是一个临时节点。在 HBase 中,每个 RegionServer 会在 ZooKeeper 上创建一个 Ephemeral Node 来注册自己的状态和信息。这样可以让 HMaster 和其他组件知道集群中各个 RegionServer 的状态,并且可以根据需要进行负载均衡和故障恢复。
HBase 有着稀疏存储的特点,即当一行数据中某些列的值为空(null)时,HBase 并不会在底层存储中分配空间给这些空值,从而节省存储空间。
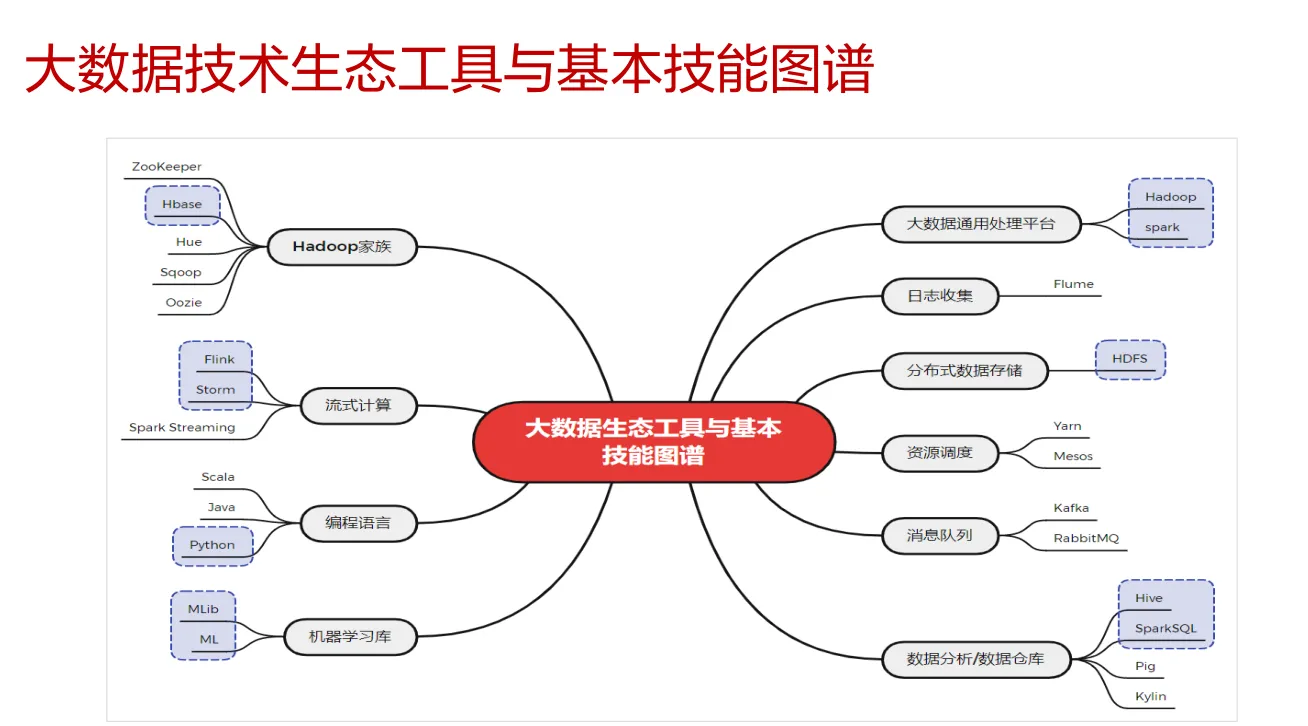
4. 大数据技术生态

Sqoop:主要作用是在 Hadoop(Hive 和 HDFS)与传统关系型数据库(MySQL、Oracle)之间进行数据传输。
extra 考点. 大数据发展(*)
- 大数据 zc 元年(2014 年 3 月)
- 大数据上升 gj 战略(2016 年 8 月)
- 数据要素市场化配置上升国家战略(2020 年 4 月)